글을 마지막으로 남긴게 어언 6월달이던가...에거~ 개발일은 해도해도 끝이 없는거 같다.
설계 단에서 커버 됐을 일을 프로그램으로 몽땅 커버하는 일을 해봤는가...눈물이 난다.
데이터아키텍처란게 그래서 중요한걸 안다. 설계뿐 아니라 기획에서 개발까지 전사적으로 아우르는
정보 아키텍처는 눈물이 날만큼 중요하다는걸 매순간 깨닫게 만들어주니 고마워 해야 하는건지......
DB를 다루는 일은 언제나 즐겁다. 그래서, 개판 오분 전인 DB를 볼때마다 화가 난다. 시간에 쫓겨 그
걸 바꾸지도 못하고 내가 하고픈 일이 DBA인지 프로그래머인지 구분하기 힘든 환경도 역시...
이런 말이 있으니...
설계자여!!! 당신이 10분을 더 고민하면 프로그래머는 1시간이 편해진다.
여기까진 잡담이자 필자의 푸념이다. 혹, 퍼간다면 위에는 편집 좀.... :)
============================================================================================
인덱스(INDEX)
인덱스를 조금만 더 파고 들어가고파서 작성해본다.
MSSQL에서 지원하는 인덱스는 개발이든 DBA로든, 개발자로 있는 이상 무지하게 듣는 말이다.
클러스터드 인덱스, 넌클러스터드 인덱스...
징글징글하다.
1. MSSQL의 인덱스 종류
① 클러스터드 인덱스 (Clustered Index)
클러스터라는 말은 사전적인 의미로
[명사]<수학> 통계 조사의 대상인 모집단의 요소를 몇 개 모은 단위체.
[명사]상호 작용을 통하여 새로운 지식과 기술을 창출할 수 있도록 기업, 대학, 연구소 따위를 모아 놓은 지역.
라고 한다. 인용한 말에 따르면 공통적으로 세가지가 눈에 들어온다.
① 특정 행위(통계조사, 상호 작용)를 위해 ② (비슷한 종류의 = 연속된) 집단을 ③ 모아놓은
이다. 이 말은 개체의 특성(개성)보다는 집단의 목적이 중요하고 집단 간의 상호 작용을 통해 시너지
효과를 노리기 위함이라고 풀어볼 수도 있다. 이렇게 하는게 뭐가 좋으냐는 실생활에서도 드러난다.
혼자 독고다이는 별로 좋지 않다. 그래서 상업지구를 만들어 특성화하면 사람들이 몰리기 마련이다.
용산이 그런 경우가 아닌가? 요즘에야 인터넷 쇼핑몰이 용산도 썰렁하게 만들긴 했지만, 옛날에는 전자제품하면 용산을 먼저 떠올렸다.
클러스터드(Clustered) 인덱스로 다시 돌아오자.
굳이 우리말로 바꾸면 (비슷한 종류의, 혹은 연속된) 집단의 목차 라고 해야 할까나? -_-;; 비슷한
놈끼리 연속해서 모아놨으니 랜덤하게 앞놈을 뽑으면 뒷놈은 앞놈과 별차이 없는 녀석일거란 추측
은 당연한듯 할 수 있다.
이쯤 했으면 이미지 하나 출연해주시고....
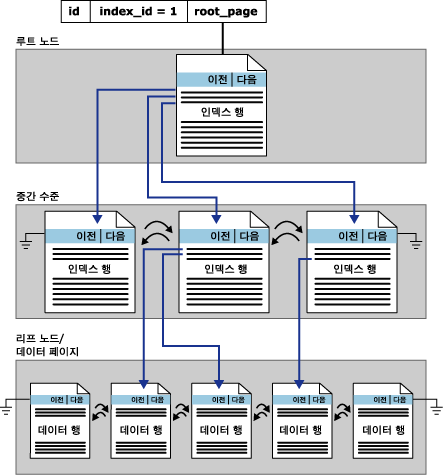
(출처 : 어디 띱어올데도 없고 온라인 북에서 가져왔다.)
클러스터드 인덱스는 B-Tree형태로 저장된다. 위 그림은 왠지 많이 보던 트리모양과는 과하게 다르긴
한데 B-Tree 맞다.
오라클 얘기를 잠시 하자면 오라클에서 인덱스 일체형 테이블(Index Organized Table)과 인덱스 분리형 테이블 (Index Ordinary Table)이 있다. 데이터 옆에 인덱스가 있느냐 없느냐 차이다. 인덱스 옆에 데이터가 있으면 좋은점과 나쁜점은 초보가 아닌 이상 당연하듯 알 수 있을거라 생각한다. 자세한 것은 책보면 되겠다. (허나, 밑에서 얘기하긴 한다.-_-;;)
클러스터드 인덱스는 오라클의 인덱스 일체+분리형이라고 해야 할까나? 인덱스를 따로 분리했다고 봤는데 리프노드를 보면 결국 데이터 페이지로 결합되어 있다. 이건 완전 짬뽕 인덱스인건가? 오라클에서는 분리형이니 일체형이니 선택할 수 있는데 MSSQL에서는 못찾은건지 몰라도 이런 기본적인 인덱스 구조를 변경하지 못한다.
인덱스 분리형의 좋은 점은 저장할때 대충(?) 넣어도 된다는 것이다. 하지만, 꺼내 쓸때를 위해서 저장한 위치를 어딘가에는 적어놔야한다는 불편함이 있을 뿐이다. 그리고, 적어놔야 할 공간도 필요하다는 것. 마지막으로 찾아가기 위해 ROWID를 통해 랜덤 I/O가 발생한다는 것. (미리 얘기하지만 요거 넌클러스터드 인덱스 구조 생각하면 되겠다. MSSQL로 보면 ROWID가 아니라 RID겠지. RID 룩업 기억하시는가?)
인덱스 일체형은 분리형처럼 어딘가에 적어놓은 주소를 보고 랜덤 I/O를 통해 한번 더 찾아가야 하는 부담은 없다. 특히나 대량의 범위를 스캔할때 실제 데이터 위치를 찾아가기 위해 발생하는 랜덤 I/O는 상당한 부담을 주기 마련인데 인덱스 일체형은 그런 부담에선 상대적으로 덜하다. 하지만, 현 컴퓨터의 구조인 폰노이만 (폰노이만 찾아보시라!!) 구조에 따라 CPU가 데이터를 처리하기 위해 디스크에서 메모리로 블록 단위로 데이터를 퍼올리는데 같은 블록 내에 원하는 데이터가 없고 여러 블록에 걸쳐 데이터가 넓게 퍼져 있다면 디스크 I/O가 엄청 많이 발생할 것이므로 성능상의 문제가 있을 것이다.
왠지 오라클 얘기인거 같아 시큰둥할거 같은데 위 내용은 중요하다. MSSQL도 해당되는 내용이다. 클러스터드 인덱스를 일체형+분리형 짬뽕으로 만든 것은 오라클의 장점을 쏙쏙 가져온 것일수도 있다. (정말일까나? 사실 모르겄다.)
이제 정리할때가 된거 같다.
MSSQL에서 클러스터드 인덱스는 오라클 입장에서 봤을때 인덱스 일체형+분리형 인거 같으나 사실 엄밀히 말하면 일체형에 가깝다. 분리형은 인덱스 경유하여 데이터를 엑세스 하는 경우에는 언제나 두번의 논리적인 엑세스가 발생한다. 하나는 인덱스를 엑세스하는 것이고 두번째는 엑세스한 인덱스에서 나온 RID를 통해 실제 데이터 페이지를 찾는 것이다. 클러스터드 인덱스는 이런 한번의 랜덤I/O가 없다. 거기에 오라클에는 없는 장점도 가져왔으니(사실 이걸 MSSQL만의 장점이라해야 되나??? 게다가 오라클도 클러스터링이라는 기능은 있다. 테이블에 별도로 생성해야 하지만...) 이 인덱스는 생성만 해도 데이터 페이지가 인덱스 키 값으로 자동으로 정렬된다는 것. 물론, 키가 자주 업데이트 된다면 그 부하는 상당하겠지만 이걸 사용하는 장점도 만만찮기 때문에 오라클도 클러스터링이라는 기능이 있는게 아니겠는가? 이것은 말그대로 키값에 따라 비슷한 데이터를 같은 블록에다 묶어주어 대량의 범위 스캔을 할때 디스크에서 하나의 블록을 메모리로 퍼온 다음에 쭉~ 봤더니 아 이 넘이 글쎄 CPU가 처리해야 할 범위의 넘들이란 말 것이다. 줄줄이 굴비처럼 묶여오니 디스크 I/O수가 많이 줄어든다. 현재의 가장 큰 병목은 디스크 속도라는 점을 감안하면 이것의 장점은 실로
님 좀 짱인듯 ≥▽=乃
범위 검색
아! 여기서 위에서 얘기한 범위 검색이라는 말을 좀 더 곱씹어 보자.
범위 검색이라는 패턴을 볼까나...1에서 100까지의 숫자가 있다. 우린 보통 1에서 10, 5에서 30 이런식으로 일련된 번호를 많이 찾는다. 날짜도 보면 2000년1월1에서 2002년 5월5일 이런식으로 검색을 많이 하지 2000년 1월 1일 찾고 2005년 5월 1일 찾고 이런식으로 대.량.의. 데이터를 띄엄띄엄 찾는 경우는 별로 없다. 이 말의 의미는 대부분은 정렬된 순서에 따라 스캔할 인덱스 첫 위치를 딱 한번 랜덤하게 찍고 나면 나머진 스캔 방식으로 찾으면 된다는 것이다. 한번 콕 짚고 난 후에 쭈~욱 읽는다. 그래서 클러스터드 인덱스는 스캔 방식으로 찾을 때도 찾고자 하는 데이터가 같은 블록에 있을 경우가 많다. 곧, 범위 검색도 탁월하다라는 결론이다.
클러스터드 인덱스로 만들면 좋은 경우 (MS의 권고 사항이다.)
1) BETWEEN, >, >=, < 및 <= 등의 연산자를 사용하여 일정한 범위의 값을 반환합니다.
클러스터형 인덱스를 사용하여 첫 번째 값을 가진 행을 찾으면 다음의 인덱싱된 값은 반드시 물리적으로 인접해 있습니다. 예를 들어 쿼리가 일정한 범위의 판매 주문 번호 간의 레코드를 검색하는 경우 SalesOrderNumber 열의 클러스터형 인덱스는 시작 판매 주문 번호가 포함된 행을 빠르게 찾은 후 마지막 판매 주문 번호에 도달할 때까지 테이블의 모든 연속된 행을 검색합니다.
2) 큰 결과 집합을 반환합니다.
3) JOIN 절을 사용하며 일반적으로 외래 키 열입니다.
3) ORDER BY 또는 GROUP BY 절을 사용합니다
② 넌클러스터드 인덱스 (Non-Clustered Index)
이건 뭐 위에서 다 파먹었다. 씁~ 얘긴 다 했는데...할건 별로 없고 일단 그림부터 껴넣자.

(출처 : 역시나 어디 띱어올데도 없고 만만한 온라인 북에서 가져왔다.)
마지막 데이터 페이지를 보라. 클러스터드 인덱스처럼 순차적으로 연결되어 있지 않고 니 맘대로 되어 있다. 힙(Heap)상에 널부러져(?) 있는 데이터 페이지를 랜덤하게 엑세스 하는 것 되겠다.
이때, 인덱스 페이지 리프 노드에서 실제 데이터를 찾는 과정을 RID Lookup 이라고 한다. (MSSQL2000에서는 Bookmark Lookup으로 나온다.)
클러스터드 인덱스는 실행계획이 시시한데 요건 한번 실행계획까지 확인해보자.
일단 테스트 환경부터...
CREATE TABLE [dbo].[TEST](
[key_col] [int] NOT NULL,
[col2] [int] NOT NULL,
[col3] [int] NOT NULL
) ON [PRIMARY]
-- 1만건의 테스트 데이터 입력
declare @i int
set @i = 0while (@i < 10000)
begin
insert test values(@i, @i%10, @i%30)
set @i = @i + 1
end
CREATE INDEX IX_TEST ON DBO.TEST(key_col) -- 넌클러스터드 인덱스 만들기
SELECT *
FROM test
WHERE key_col = 2
라고 실행해 봤더란다.
SET SHOWPLAN_TEXT ON
이라고 해서 실행계획을 보니
StmtText
------------------------------------------------------------------------------------------
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000]))
|--Index Seek(OBJECT:([TEST].[dbo].[TEST].[IX_TEST]), SEEK:([TEST].[dbo].[TEST].[key_col]=(2)) ORDERED FORWARD)
|--RID Lookup(OBJECT:([TEST].[dbo].[TEST]), SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD)
라고 한다.
그래픽을 좋아하는 사람을 위해...
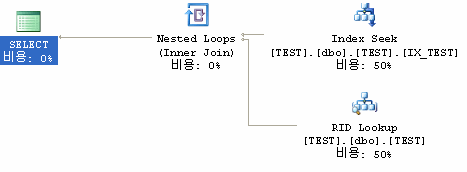
요렇다고 한다.
참고로 TEXT로 보는 법에도 익숙해지길 권한다.
텍스트를 보니 두번째 줄에
Index Seek(OBJECT:([TEST].[dbo].[TEST].[IX_TEST]), SEEK:([TEST].[dbo].[TEST].[key_col]=(2)) ORDERED FORWARD)
라고 나와 있다. 인덱스를 이용하여 SEEK를 했는데 정렬 방식이 오름차순이니 정렬 순에 따라 숫자가 낮은 놈부터 인덱스 페이지에서 뒤져서(ORDERED FORWARD) 2를 찾았다.
그 다음 줄에 RID Lookup을 하여 양쪽의 결과를 Nested Loops 방식으로 INNER JOIN한다.
재밌는 사실이다. 인덱스 페이지에서 찾은 결과(주로 키값만 있겠지?)와 데이터 페이지(키와 데이터)를 조인한다. 여기서 Nested Loops라는 건 우리말로 중첩루프라고 해서 이중 For문 생각하면 된다.
그렇다면 의문...중첩루프 방식으로 조인해서 최종 결과물을 뽑아오면 대량의 데이터를 가져오는건 문제가 되지 않을까? 글쎄...문제가 되겠지. 그래서, 넌클러스터드 인덱스만 생성되어 있는 경우에는 선택도가 좋은 경우에만 인덱스를 사용하는 것 같다. 가령 넌클러스터드 인덱스에 유니크 제약조건을 같이 걸어주면 반드시 넌클러스터드 인덱스를 사용한다. 하지만, 선택도가 10% 이상이 되면 인덱스를 사용하지 않고 테이블 스캔을 한다. 테스트를 해보니 10%라기보다 1%정도로 보인다. 테이블이 대용량이면 그 이하도 되겠지.
한가지 더 얘기하자면 위의 Index Seek 비용과 RID Lookup 비용이 50%:50%로 동일한데 이건 한건을
찾아서 그런 것이고 여러 건을 찾게 된다면 RID Lookup 쪽의 비용이 올라간다. 인덱스를 탐색하는건
그만큼 엄청 빠르다는 것이고 이 RID를 바탕으로 실제 주소를 찾는 과정은 물리든 논리든 I/O가 발생한다는 점에서 그만큼 느리다는 얘기다. 결국 넌 클러스터드 인덱스의 해결과제는 RID Lookup 비용을 어떻게 하면 최소로 할 것인가에 달렸다. 그래서, 가급적이면 비슷한 데이터는 같은 블록에 입력하는게 좋다. 클러스터링 팩터를 높인다고 하지요? 예를 들면 넌클러스터드 인덱스만 잡혀 있는 테이블엔 넌클러스터드 인덱스 키값으로 정렬해서 다시 넣어주면 나름 성능향상에 도움을 줄수도 있겠다. 물론, 인덱스 선택도나 사용패턴과 같은 다른 부가적인 것도 봐야겠지만...
넌클러스터드 인덱스로 만들면 좋은 경우, MS의 권고 사항이다.
1) JOIN 또는 GROUP BY 절을 사용하는 쿼리
조인 및 그룹화 작업과 관련된 열에는 비클러스터형 인덱스를 여러 개 만들고 외래 키 열에는 클러스터형 인덱스를 만듭니다.2) 큰 결과 집합을 반환하지 않는 쿼리
3) WHERE 절과 같이 정확히 일치하는 값을 반환하는 쿼리의 검색 조건에 자주 사용되는 열을 포함하는 쿼리
오늘은 여까지....가만보니 글을 안쓰는 이유가 있는거 같다. 한번 쓰면 한 4~5시간은 쓰니...
이걸 쓰느니 책 한자를 더 보던가, 잠을 자고 말지란 생각도 들고....
사실 좀더 하드웨어적으로 더 들어가고픈데 MS계열은 여기서 더욱 깊이 들어갈 수 있는 책이나 자료가 부족하다. 쫌 더 깊이 들어갈라면 MS도 오픈 소스를 해야 되려나???
[출처] [본문스크랩] [MS-SQL2005] 인덱스 고찰|작성자 진카자마