MS-SQL의 실행계획에 대한 고찰이다.
(아침부터 열심히 썼던 sp_who 고찰은 잠시 접어둘란다. ㅡㅜ)
MS-SQL은 실행 계획을 GUI형태로 보여준다. MS의 머리들이 만든 것이니 어련하겠으랴...
실행계획을 논하기에 앞서 Index에 대해 잠시 얘기하는게 좋겠다.
(Index도 언젠가는 심도있게 다뤄보고 싶긴 하나 여기서는 B-Tree가 어쩌고 노드가 어쩌고
심도있게 안나간다.)
1. Index
Index를 얘기할때 많이 드는 비유는 책이다. 그리하여, 본인도 책이란 좋은 비유의 도구를 이용
하고자한다.
책에서 SQL이란 단어를 찾으려한다. 벌써부터 숨이 탁탁 막혀오지 않은가? 물론, SQL책에서
SQL이 빈번히 많이 나오는 단어인것은 분명하므로 몇장 안되서 금방 찾지 싶다. 그럼, 인증이
란 단어를 찾고 싶다. 허허...어떻게 할까? 우연히 페이지를 열었는데 찾았다는건 정말 우연히
인것이고 책 첫페이지부터 하나하나 찾기 위한 비용은 정말 많은 인고의 시간이 필요하다.
그래!! 이때 우리의 선택은 책 맨 뒷장의 찾아보기 또는 맨 앞장의 목차를 찾아보는게 가장 빠르
고 정확하다. 인덱스는 이런것이다. 찾는 수고를 덜어주는 길잡이 도구...
좀더 얘기해보자.
인덱스 중에는 클러스터드 인덱스(Clustered Index), 넌클러스터드 인덱스(NonClustered
Index)가 있다.
클러스터드 인덱스는 목차와 같이 페이지가 정렬되어 있어 범위 검색과 점 검색에는 탁월하다.
넌클러스터드 인덱스는 찾아보기와 같아서 점검색(Match 검색, A=B)에 탁월한 성능을 발휘한
다.
클러스터드 인덱스는 Primary Key를 설정하면 자동으로 생성되며 테이블 당 한개만 가능하다.
(혼동하지 말자. 한 테이블에 한개 컬럼만으로 구성한다는 의미가 아니다. 한 테이블에 여러
개의 컬럼에 잡을 수도 있다.)
넌클러스터드 인덱스는 테이블 당 249개까지 가능하다. (근데 명심할 것은 Index가 많다고 좋
은건 아니다. Index가 많으면 DML문이 난무한 OLTP환경에선 최악일 수 있다.)
위의 사항을 정리하여,
1) Clustered Index
- 테이블 당 한개만 잡을 수 있다.
- 범위 검색과 점 검색에 탁월한 성능 발휘
- Primary Key를 잡으면 자동으로 Clustered Index 생성
- 데이터가 순서대로 정렬(오름차순, 내림차순 선택 가능)
2) Non-Clustered Index
- 테이블 당 249개까지 가능
- 점 검색에 탁월한 성능 발휘
- 또한 일반적으로는 Clustered Index가 Non-Clustered Index보다 검색 속도가 빠르다.
우선, 이정도만 알아보고 이제 실행계획을 들어가자.
2. 실행계획
2-1. 실행계획을 보려면

1) 도구모음에서 빨간 박스 친 녀석을 선택
2) 상단 매뉴에서 쿼리 -> 실제 실행계획 표시
3) Ctrl + M
을 해주면 된다.
2-2 실행계획

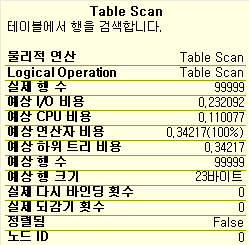
Table Scan :
일반적으로 많이 나오는 녀석이다. 사실, 많이 나오면 안되는 녀석이기도하다. 한마디로 전체
테이블을 다 뒤진다는 것이며 인덱스를 사용하지 않는다는 말이다.
이게 나오는 경우는
Index가 없는 테이블을 검색할때이다.
비용은 전체 테이블 스캔만큼 든다. 다 가져와야 하니...뭐 당연한 얘기...

Clustered Index Seek :
위와는 달리 전체 테이블을 다 뒤지지 않고 클러스터드 인덱스를 사용하여 찾았다는 의미다.
당연 위와 비교하여 성능이 몇배는 달라졌다.
이게 나오는 경우는
where절에 클러스터드 인덱스가 걸린 컬럼으로 검색을 했을때다.
->
select * from table_name where a=0
select * from table_name where a > 0 and a < 1000

Clustered Index Scan :
말그대로 클러스터드 인덱스 내에서 스캔을 했다라는 의미다. Scan을 했으니 테이블 전체
Scan과 비슷한 성능을 가진다.
Table Scan 비용 :
select * from Table로 검색(컬럼에 어떤 Index도 없음)
Clustered Index Scan 비용 :
select * from Table로 검색 (컬럼에 Clustered Index 생성)

이제 실습도 한번 해보자.
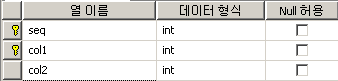

위와 같이 테이블을 만들고 데이터를 넣은 다음에 한번 테이블 스캔은 언제 일어나나 함 보자.
PK로 키를 잡았다는 것은 Clustered Index를 만들었다는 의미다. 한번 더 얘기하지만, 클러스
터드 인덱스는 테이블 당 하나이지 컬럼 당 하나만 생성할 수 있는건 아니다.
index_keys에 seq, col1이 순서대로 잡혀있다.
① select * from test where seq = 100
② select * from test where col1 = 100
③ select * from test where col2 = 100
④ select * from test where seq = 100 and col1 = 100
1의 경우는 Clustered Index Seek
2의 경우는 Clustered Index Scan
3의 경우는 Clustered Index Scan
4의 경우는 Clustered Index Seek
각각 일어난다. 한가지 규칙은 seq가 포함되느냐 안되느냐에 따라서 Clustered Index Seek를
할 것이냐 Clustered Index Scan을 할 것이냐를 결정한다. 그래, 중요한건 Index의 키값의 제
일 첫번째 녀석이 포함되면 Seek를 하는 것이고 포함되어 있지 않으면 Scan을 한다는 것이다.
2번 같은 경우
비용도 한번 볼까?

놀랍게도 Table 스캔과 비슷한 비용이 든다. (위쪽 실행 비용과 비교해보자.)
이 이유는 어찌보면 당연하다.
이 이야기를 하기 전에 한가지만 얘기해두자. 현재 거의 모든 RDBMS에서는 데이터 페이지와
인덱스 페이지를 분리해놓는다. 이렇게 하면 왠만해서는 모든 쿼리들이 인덱스를 이용하게 되
어 있어 보관상의 불편함은 있을지언정 검색 속도는 올라가게 되어 있다. 특히나 커버드 인덱
스(covered index:나중에 다시 논의하겠다.)를 사용하게 되는 경우에는 인덱스 페이지 레벨에
서 모든 작업이 마치기 때문에 크레이지(craze) (??) 속도가 나게 되어 있다. (광속도)
(이 이야기는 몰라도 되나 인덱스 페이지와 데이터 페이지를 분리해놓는다라는 것만 기억하면
된다.)
다시 돌아와서,
테이블 스캔의 경우는 인덱스를 검색하지 않고 데이터 페이지 자체를 탐색하여 찾는다. 클러스
터드 인덱스 스캔의 경우는 인덱스를 검색하긴 하는데 어짜피 최종 리프 레벨은 데이터 페이지
다. 그러다보니 똑같을 수 밖에 없다.
고속도로 휴계소가 목적지가 아닌 이상 고속도로를 타고 이모, 삼촌, 외할아버지 댁을 다 들리
나 국도를 타고 이모, 삼촌, 외할아버지 댁을 들리나 어짜피 다 똑같은거다.
(비유가 적절한진 모르겠다. 대충 넘어갓~~)
정리하면 ..
테이블 스캔 : 직접 데이터 페이지 탐색
클러스터드 인덱스 스캔 : 인덱스를 통해 데이터 페이지 탐색
이렇게 된다는 말이다. 그러니 똑같다. -,.-;; (어찌보면 클러스터드 인덱스 스캔이 인덱스를 타
니까, 인덱스 타는 비용이 더들것도 같은데 결과가 저러니 일단 똑같다고 보자.)
그럼...왜 두번째 컬럼도 Clustered Index로 잡혀 있는데 Scan을 하는 것일까?
(둘째도 자식은 자식이잖아 >.< 왜 첫째만....)
Index 키는 seq, col1로 클러스터드 인덱스이므로 인덱스를 생성할 당시 마치
select * from test
order by seq, col1
를 한 것 같은 효과로 정렬이 되어 있다.
ㄱ, ㄴ, ㄷ, ㄹ .. ㅎ 으로 정렬되어 있는 [국어사전]을 생각해볼까?
국어사전을 보면 말이지 각 자음의 시작 페이지에 탭을 해주거나 각 자음 페이지 별로 깊이 파
놓거나 아님 최소한 색칠이라도 해놓잖은가? 간만에 국어사전 옆둥이를 한번 살짝 봐주자고...
이제 돌아와서...
seq가 ㄱ, ㄴ, ㄷ, ㄹ .. ㅎ 의 힌트를 주는 탭 같은거라면 col1은 아, 야, 어, 여, .. , 이의 힌트
를 준다고 보자. 여기서 [홍]이라는 단어를 찾을라면 seq의 가치는 절대적이다. seq 없이 아,
야, 어, 여, .. , 이 의 힌트만으로 찾을 바에야 SQL서버는 차라리 Scan을 하자라는 판단을 한
모양이다.
즉, 성능의 극대화를 노린다면 클러스터드 인덱스의 제일 첫 컬럼은 가장 많이 검색하는 컬럼,
거의 꼭 필요한 컬럼으로 지정해놓으면 좋을 것이란 판단이 선다.
(계속.....)